Cassandra¶
Cassandra 是一种早期的 NoSQL 数据库,采用tabular存储和key-value存储之间的混合设计。它旨在为需要快速读写性能的应用程序存储数据。参阅NoSQL数据库对比查看Cassandra和其他NoSQL数据库的比较。
架构¶
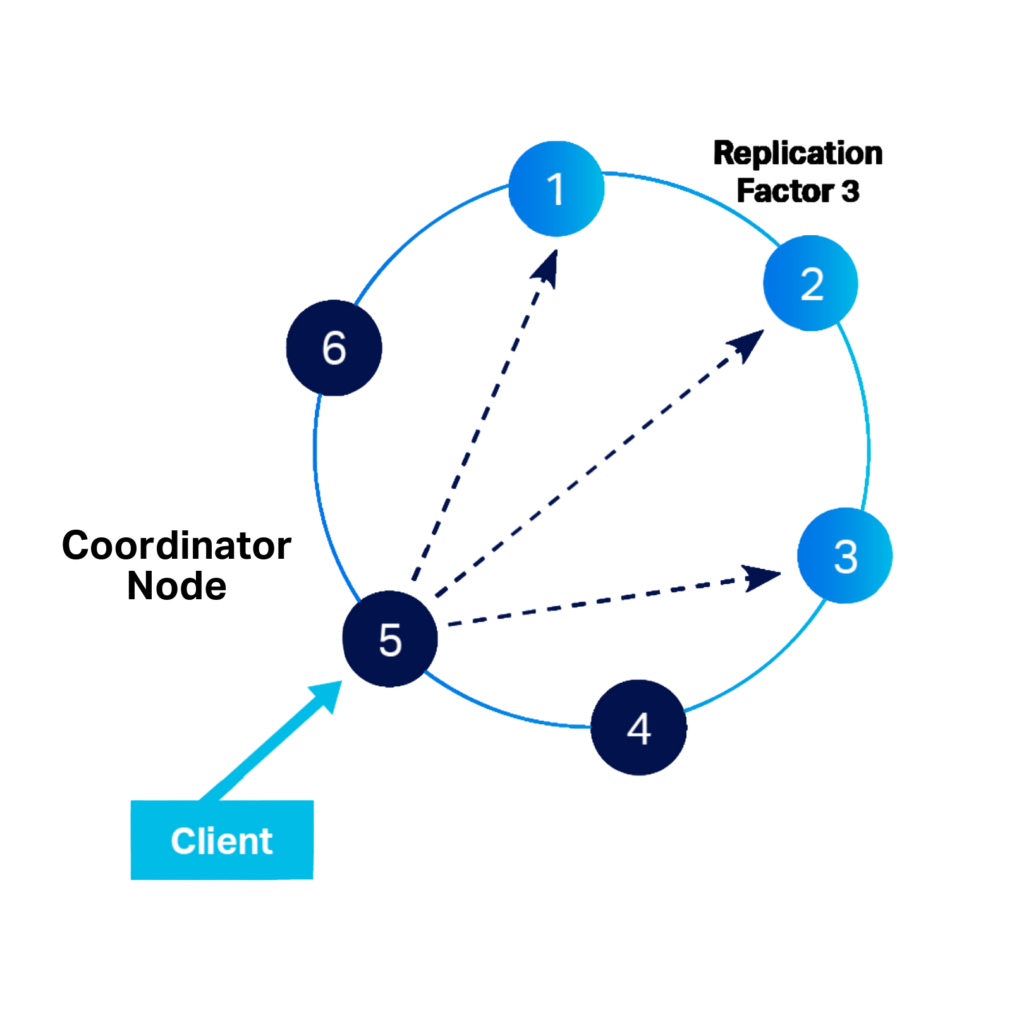
Cassandra集群是一组实例,称为节点,连接在对等“不共享”分布式架构中。没有主节点,每个节点都可以执行所有数据库操作,每个节点都可以服务于客户端请求。数据基于其分区键的一致哈希在节点之间进行分区。一个分区有一个或多个行,每个节点可能有一个或多个分区。但是,一个分区只能驻留在一个节点上。
数据有一个复制因子,它决定了应该制作的副本(副本)的数量。副本会自动存储在不同的节点上。
首先从客户端接收请求的节点是协调器。协调器的工作是将请求转发给保存该请求数据的节点,并将结果发送回协调器。集群中的任何节点都可以充当协调器。
数据模型¶
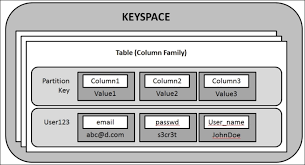
- Keyspace:数据容器,相当于关系数据库的schema或者database。
- Table:又叫Column Family,由Primary Key和一系列Column组成。数据存储在Row中。
- Column:组成Table的数据结构,每个Column关联到具体的数据类型,如integer,text,等。
主键(Primary Key)和分区键(Partition Key)¶
如何选择primary key和partition key对于在集群中均匀分布数据很重要。partition key用于在节点之间划分数据。partition key是从primary key的第一个字段生成的。在执行查询的时候,更少的分区可以提高查询效率。
查询驱动的建模¶
Cassandra不支持join,因此所有必需的字段(列)必须组合在一个表中。由于每个查询都由一个表支持,因此在称为非规范化的过程中,数据会在多个表中重复存储。数据重复和高写入吞吐量用于实现高读取性能。
有限的查询功能¶
- 不支持JOIN。相关操作要么在客户端完成,要么使用一个新的表。
- 没有外键
- ORDER BY只支持primary key。
- WHERE一般只能作用于primary keys。如果查询的数据可以被限制到某个节点上,则可以联合ALLOW FILTERING关键字作用在非primary key上。
SELECT * FROM year_table WHERE partition_key = ? AND non_clustering_column = ? ALLOW FILTERING;
- 分页只支持基于token(LIMIT)的方式,不支持OFFSET,无法实现如查询第N页的功能。
SELECT * FROM your_table WHERE partition_key = ? AND clustering_column > ? LIMIT ?;
索引和试图¶
- 二级索引:赋能非primary key上做过滤
- 常规二级索引:每个索引都在背后创建了一个和源数据表放在一起的表。如果一个查询只针对索引字段而不包含partition key,则所有节点都会被扫描,延时巨大。
- SSTable-Attached Secondary Index (SASI):新型的二级索引,对文本搜索有优化,比常规二级索引性能要高。
- 物化视图:
- Cassandra自动维护的一个表。可以用与源数据表不一样的partition key,但只能使用最多一个源表的非primary key字段作为primary key。
- 当有数据更新到源数据表,更新将会自动应用到视图,但这个过程是异步的,会有延时。
可调节的一致性和可用性模型¶
Cassandra 基于 CAP 定理,它允许用户在一致性(Consistency)和可用性(Availability)之间做出选择。在分布式系统中,完全的一致性和100%的可用性是无法同时实现的,Cassandra 通过其可调节的一致性和可用性模型来平衡这两者,既可实现偏重于可用性的最终一致性,也可以实现强一致性。
副本因子(Replication Factor, RF)¶
副本因子定义了一个数据集(如Keyspace)中的数据在集群中应该存储多少份副本。例如,RF=3 意味着每个数据项有三个副本。
- 容错性:更高的副本因子可以提高容错性,因为数据在更多的节点上有副本。
- 读写性能:副本因子也影响读写性能。更多的副本意味着写操作需要更新更多的节点,但同时也可能提高读操作的速度,因为有更多的节点可以响应读请求。
一致性模型¶
Cassandra 的一致性模型允许用户在每次读写操作时选择一个一致性级别。这个级别决定了操作成功所需的最小副本响应数。
常见的一致性级别(Consistency Level)¶
- ONE:只需一个副本响应。
- QUORUM:大多数副本响应。对于给定的 RF, 需要
(RF/2) + 1副本响应。 - ALL:所有副本响应。
(Cassandra还有其他一致性级别没有列出)
强一致性的公式¶
Cassandra 中判断是否实现了强一致性(Strong Consistency),可以通过一个简单的公式来评估,这个公式涉及到副本因子和一致性级别。强一致性意味着所有的读取操作都能立即看到之前写入操作的结果,即系统在任何时刻都是一致的。强一致性可以通过公式进行判断:R + W > RF
其中:
- R 是读操作的一致性级别所需的最小响应副本数。
- W 是写操作的一致性级别所需的最小响应副本数。
- RF 是副本因子,即数据在集群中的副本数。
例子¶
假设 Cassandra 集群的副本因子 RF=3,我们考虑以下两种情况:
- 读和写操作都设置为 QUORUM:
- 在 RF=3 的情况下,QUORUM 的副本响应数是
(3/2) + 1 = 2。 - 因此,
R = W = 2,所以R + W = 2 + 2 = 4。 4 > 3 (RF),因此满足强一致性。
- 在 RF=3 的情况下,QUORUM 的副本响应数是
- 读操作设置为 ONE,写操作设置为 QUORUM:
- 对于读操作
ONE,R = 1。 - 对于写操作
QUORUM,W = 2。 - 因此,
R + W = 1 + 2 = 3。 3 = 3 (RF),这种情况下不满足强一致性,则读请求可能返回非最新的数据。
- 对于读操作
参考资料¶
- https://www.instaclustr.com/blog/cassandra-vs-mongodb/