Kafka¶
使用¶
Topoic¶
| Configuration | Description | Default Value | Example (Critical Scenario) |
|---|---|---|---|
| unclean.leader.election.enable | Indicates whether to enable replicas not in the ISR set to be elected as leader as a last resort, even though doing so may result in data loss. | false |
false |
Producer¶
| Configuration | Description | Default Value | Example (Critical Scenario) |
|---|---|---|---|
batch.size |
Specifies the size of message batches sent by the producer. Larger batches improve throughput but increase latency. | 16KB | Experiment with different sizes based on message size and network bandwidth. Use smaller batches for critical data to minimize potential data loss on failures. |
compression.type |
Enables compression of messages before sending. Reduces network usage but adds CPU overhead. | none (default) |
Compression can be beneficial for critical data to improve throughput, but ensure adequate producer resources. |
acks |
(Described above) | As mentioned above, use all for critical data. |
|
linger.ms |
Controls the time the producer waits for additional messages before sending a batch. | 0 (default) | Use a low value for minimal latency, but consider a slightly higher value for critical data to potentially accumulate more messages in a batch, reducing network overhead. |
enable.idempotence |
Ensures that a message is written only once to the topic, even if retries occur due to failures. | false (default) |
Enable idempotence for critical data to prevent duplicate messages. Requires acks=all. |
max.in.flight.requests.per.connection |
The maximum number of unacknowledged requests the client will send on a single connection before blocking. | 5 | If this value is set to larger than 1, set enable.idempotence to true or disable retries to preserve the ordering |
retries |
Setting a value greater than zero will cause the client to resend any record whose send fails with a potentially transient error. | 2147483647 | Use default, use delivery.timeout.ms to control retry behavior. |
delivery.timeout.ms |
An upper bound on the time to report success or failure after a call to send() returns. | 120000 |
Consumer¶
| Configuration | Description | Default Value | Example (Critical Scenario) |
|---|---|---|---|
fetch.min.bytes |
Sets the minimum amount of data a consumer fetches in a single request. Larger values improve efficiency but increase latency. | 1KB | Experiment with values to optimize efficiency. However, prioritize data consumption for critical topics to minimize message backlog. |
fetch.size |
Defines the maximum amount of data a consumer fetches in a single request. | 1MB (default) | Adjust based on network bandwidth and message size. Ensure sufficient fetch size for critical topics to handle message volume. |
session.timeout.ms |
Controls how long the consumer can remain inactive before being disconnected by the broker. | 30000 (default - 30 seconds) | Use a higher value (e.g., 60 seconds) for critical consumers to tolerate potential network delays and avoid unnecessary reconnections. |
enable.auto.commit |
Enables automatic commit of offsets by the consumer. Disabling allows manual control but requires more management. | true (default) |
Consider disabling auto-commit for critical scenarios to ensure strict control over offset processing and avoid data loss during failures. Implement a reliable mechanism for manual commits. |
Metadata¶
Kafka 的 metadata(元数据)主要包含了与 Kafka 集群的管理和操作密切相关的信息。这些信息对于 Kafka 的正常运作至关重要,包括但不限于以下几类:
- 主题(Topics)信息:包括主题的名称、分区(partitions)数量、副本(replicas)的分布情况、以及与这些主题相关的配置参数。这些信息对于消息的存储和检索非常关键。
- 分区(Partitions)信息:每个主题都会被分成多个分区,这些分区的元数据包括它们所在的 broker、每个分区的 leader 以及 follower 副本的情况。
- Broker 信息:Kafka 集群由多个 broker 组成,broker 的元数据包括它们的 ID、地址(IP 或 hostname)、端口等信息。这对于客户端和 broker 之间的通信至关重要。
- 消费者组(Consumer Groups)信息:包括消费者组的 ID、所订阅的主题以及每个消费者当前正在读取的分区和偏移量(offset)信息。这些信息对于确保消息被正确分发给消费者和消息消费的负载均衡非常重要。
- 偏移量(Offsets)信息:Kafka 用于跟踪消费者对于特定分区已经读取到哪个位置的数据结构。每个消费者组对于其订阅的每个分区都有一个当前偏移量,这有助于消费者在断开和重新连接时从上次停止的位置继续读取数据。
- 访问控制列表(ACLs)信息:包含关于哪些用户或消费者组可以对特定的主题执行读取或写入操作的安全信息。
Kafka 集群使用 ZooKeeper(尽管新版 Kafka 正在逐步淘汰 ZooKeeper 的依赖)来存储和管理这些元数据信息,以保证集群的高可用性和数据的一致性。随着 Kafka 新版本的发布,元数据的存储和管理机制也在不断进化,例如引入了 Kafka Raft (KRaft) 模式来管理元数据,目的是简化架构并提高性能。
如何Size一个集群¶
当需要支持High Availability和Durability时,Kafka集群有最低的要求:
- Topic的Replication Factor必须大于1,这样Topic的数据会被复制到其他节点,数据不会因为某个节点失败而丢失。
- 如果Replication Factor设置成2,则min.insync.replica必须也设置成2,否则即使Producer使用acks=all都无法保证消息绝对被正确写入。但这样设置标识一旦当某个replica失败时,这个topic就无法被写入,可用性是比较差的。建议Replication Factor设置成3,min.insync.replica设置成2,则topic允许一个replica失败。
- 当Replication Factor设置成3,则代表集群应该至少需要有3个broker节点。这3个节点要分别部署在不同的Rack或云的AZ中,以获得最大的可用性。Topic的partitions应该设置成3的倍数,以使得这些partition能够被平均地分布在不同的broker节点上。
- 基于实际的使用场景,使用kafka-producer-perf.sh和kafka-consumer-perf.sh脚本来压测集群,调节各种参数,以判断是否需要增加broker。Broker数量以3的倍数增加,如6,9,12等。Topic的partition数量也建议以3的倍数来配置,如12。
事务和Exactly Once¶
幂等Producer¶
当Kafka Producer发送消息给broker后,broker会发送ack给Producer。由于ack会丢失,或者broker在持久化了消息数据后在还没来得及发送ack时就崩溃,Producer会因为收不到ack而重新发送消息。这会使得相同的消息被broker持久化而导致Consumer收到重复的消息。这就是At Least Once Semantic。
在版本0.11后,Kafka支持了幂等Producer功能,即在配置了enalbe.idempotence = true后,Kafka可以保证重复发送的消息对同一个partition只会被写入一次(原子性写入)。而使用Transaction API更可以使原子性写入横跨多个partition,即多条消息要么同时被写入,要么都不被写入。这对End to End Exactly Once提供了支持。
End to End Exactly Once¶
在很多数据处理的场景,特别是流式处理(Stream Processing)的场景中都有精确计算有要求(也就是End to End Exactly Once Semantic支持)。这体现在consume-transform-produce工作流中支持事务,即:从Kafka读取数据,处理数据,然后再写回Kafka的场景。由于消息被消费后的Consumer Offset提交也是消息写入,幂等Producer也实现了End to End Exactly Once。
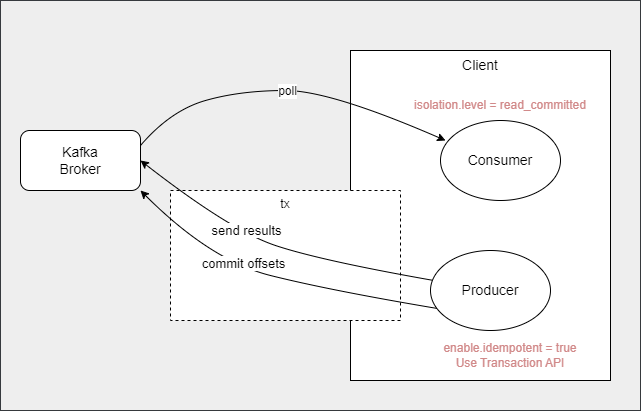
注意:如果Client的数据处理单元中除了将结果输出回Kafka外,还有其他外部系统的交互(如数据库,或调用其他系统API),则要手工处理这些系统的事务补偿。而由于无法将Kafka的事务和数据库的事务绑定在一起,或保证事务补偿API能被正确调用,技术上通常很难达到这个范围内的End to End Exactly Once。
Rebalancing¶
当有新的Consumer加入到一个Consuerm Group或者有Consumer离开,Rebalancing会被触发,以重新分配partition给现有的Consumer。有可能是以下场景:
- 应用startup,shutdown,scale-up,scale-down
- Consumer因为内部或网络原因无法响应心跳
- Consumer闲置时间过长
- Topic增加了partition
Rebalancing会带来一系列的副作用,如延时增大和吞吐量降低。如果Consumer没有适当处理commit,还有可能导致数据重复处理和或丢失。
从版本2.4开始,Kafka支持incremental cooperative rebalance。相比以前的stop the world,新的策略将rebalance拆分为更小的子任务,Consumer在这些子任务完成时继续消费数据。因此,rebalance完成得更快,对数据处理的中断更少。
Spring Kakfa¶
Spring Kafka是Spring生态圈中基于Kafka的封装。它使得更容易和Spring集成,并提供Spring风格的API接口以支持Kafka的使用,如:
- 通过application.yaml配置Producer和Consumer,大幅简化配置
- KafkaTemplate用于发送消息,KafkaListener用于接收消息
- 在原生Kafka API之上增加了新功能:
- Retry重试机制
- DLQ死信队列的支持
- 提供了KafkaTransactionManager,可以和Spring的其他TransactionManager联合在一起使用。如在场景consume-transform-db-produce场景中,DB和Kafka的TX将联动,确保DB成功后才提交Kafka的TX。注意:这并不能确保Kafka的TX最终一定成功。
Spring Cloud Stream的Kafka Binding是基于Kafka Spring实现。
Kafka Stream¶
Kafka Streams 是Kafka的一个客户端库,用于构建实时流式处理应用程序和微服务,处理的数据存储在 Kafka 集群中。它使用了以下概念:
- KStream:代表一个记录的流,是处理的基本数据结构。它允许你对数据进行映射、过滤、聚合等操作。
- KTable:代表一个变更日志流的表视图,适用于存储和更新结果,如聚合的计算结果。它在Kafka中是作为Compacted Topic存储的。
- GlobalKTable:与 KTable 类似,但每个 Kafka Streams 实例可以访问全部数据,而不仅仅是分配给该实例的数据分区。
- Topology:数据处理的逻辑结构,定义了数据流从输入到输出的整个过程。开发者通过构建拓扑来实现具体的流处理逻辑。
- State Store:在有状态的流式处理中用于存储状态,可基于内存或RocksDB。Kafka为每个State Store创建Changelog Topic用于灾难恢复。

Kafka Streams 应用可以作为常规的 Java 应用部署,不需要专门的处理集群,简化了操作和维护。可以通过增加应用实例来水平扩展处理能力。但因为它是依赖Kafka作为中间存储,当在流处理中发生key的改变时,数据要写回Kafka再读出,会产生一定的延时。
Windowing¶
- Hopping:TBD
- Thumbling:TBD
- Session:TBD
- Sliding:TBD
Window grace priod
Co-Partitioning¶
Co-partiioning 是 kafka Stream 的基本概念,它不允许两条不是 Co-partition 的流join在一起。参与join的两条流必须符合3个标准,才可以说它们是 Co-partitioning 的:
- 数据必须要有相同的keying策略。
- key 的数据类型一致
- key 的序列化方式一致
- Topic的partition数量必须是相同的。
- Topic必须具有相同 Partitioning Strategy。
Kafka Streams 提供了 KStream.repartition 方法,允许对流进行重新分区,使其符合join的条件。注意,重新分区方法不会影响源 Topic。
Processor API and Punctuation¶
Punctuation - Stream time - Wall clock time
TBD
ksqlDB¶
TBD
运维注意事项¶
防止数据丢失¶
通过不同的配置可以将Kafka配置成倾向可用性的AP系统或者倾向一致性的CP系统。如果要求不允许数据丢失,即CP系统,需要按以下配置:
- Topic配置
replication.factor >= 3:确保同一份数据会被复制到3个或以上的replica中。如果设置成2,则为了保持一致性,min.insync.replicas要设置成replication.factor,否则Producer端acks=all和acks=1等价,即只写入Leader,但Leader不确保写入磁盘。而min.insync.replicas设置成replication.factor则可用性差,任何一个replica故障都缺失可用性。 - Topic配置
min.insync.replicas >= replication.factor/2 + 1:确保大多数ISR被成功写入后,brokder返回写入ack=all。为了使集群具备一定的容错性,一般不会设置成min.insync.replicas = replication.factor,不然当有任何一个replica故障都会缺失可用性。 - Topic配置
unclean.leader.election.enable = false:确保当Leader故障后,只能由ISR被选举成为新Leader。 - Producer端配置
acks=all:确保大多数ISR被成功写入才返回ack。
注意,以上配置只保证没有数据丢失,但有可能会重复写入,即At Least Once。要实现只Exactly Once,要配置Producer端配置enalbe.idempotence = true。
| Producer Delivery Semantic | Configuration |
|---|---|
| At most once | acks=0acks=1 (min.ISR=1) |
| At least once | acks=all (min.ISR>1)retries>1 |
| Exactly once | acks=all (min.ISR>1)retries>1enable.idempotence=true |
性能监控¶
- 关注Consumer Lag - Consumer提交的Offset相对Producer的最新消息的差值,反应了消费滞后情况。可以使用Spring Boot Actuator配合Micrometer来在Prometheus中监控指标。
参考资料¶
- https://www.confluent.io/blog/exactly-once-semantics-are-possible-heres-how-apache-kafka-does-it/
- https://www.baeldung.com/kafka-exactly-once
- https://redpanda.com/guides/kafka-performance
- How Co-Partitioning Works in Kafka Streams